全民学Python
Python这门语言虽然早在1989年圣诞节期间就被Guido van Rossum创造了出来,但近几年却突然在国内开始流行了起来:网站插入广告、培训机构宣传,甚至朋友圈推荐广告都可见Python的踪影。
如此高的出现频率也吸引了很多非互联网行业的人试图学习了解,大有一种全民学Python的趋势。
了解Python
相比其他语言,Python的哲学就是简单优雅,尽量写容易看明白的代码,尽量写少的代码。总之,代码量少是它的一大特点,代价就是运行速度慢,因为Python是动态的、解释性语言。
用Python可以做什么?
Python最广泛的应用大概就是用来爬虫了,我们可以通过它编写一些小工具来爬取数据;还可以做网站或者游戏的后台。
有过其他语言开发经验的人学习Python是很好上手的,毕竟各种语言大体离不开变量、函数、对象这些概念,而且Python有很多第三方库可以帮助我们快速实现一些功能。0经验的小白也不要担心,推荐通过廖雪峰的Python教程学习,案例浅显易懂,搭配在线编辑器学习效果很不错,这里就不花费篇幅介绍一些基础知识了。阅读后续内容前你需要简单了解函数的使用、类和实例、http请求、BeautifulSoup库的使用、os文件读写、re正则匹配……以便更好地理解。
需求分析及实现思路
作为一个音乐爱好者,我首先想到要爬取的数据就是歌曲,那就索性把批量下载歌曲作为我们通过Python来实现的功能。
通过一系列的探究,最终实现的功能是通过搜索歌手名字自动批量下载其热门歌曲。
整体的思路如下:
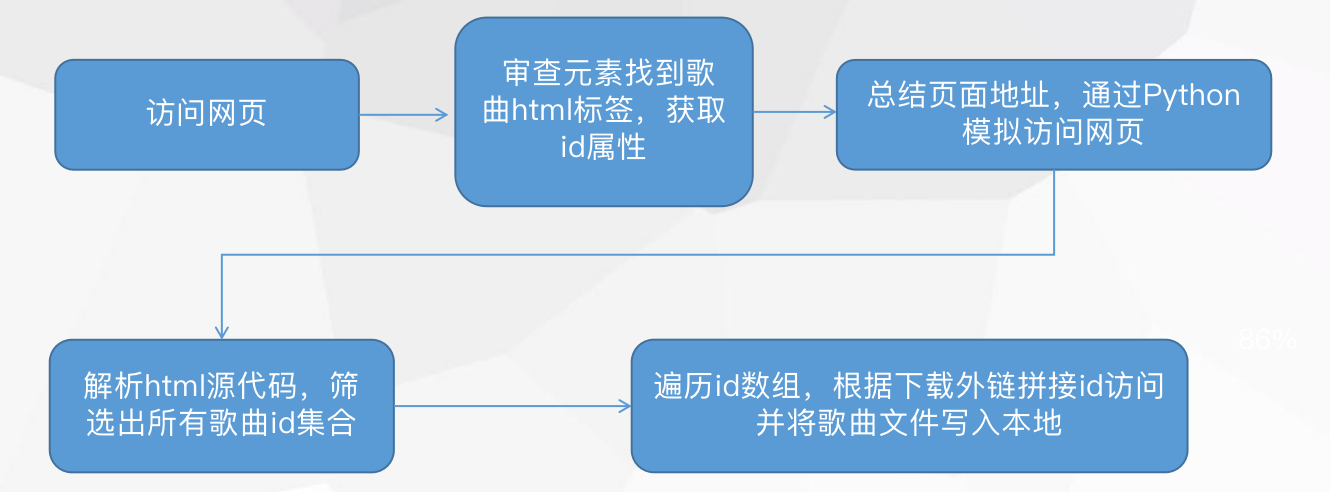
已知前人总结的网易云下载外链地址为:http://music.163.com/song/media/outer/url?id=xxx,xxx为歌曲id,所以问题就简单化了:我们只需要批量获取歌曲的id,再通过下载外链拼接id一首一首下载即可。
那么这些id从何而来?没错,通过网页。
分析网页
我们访问网易云音乐的网页端,随便进入一个歌单,审查元素选取其中一首歌曲会定位到它的HTML树。
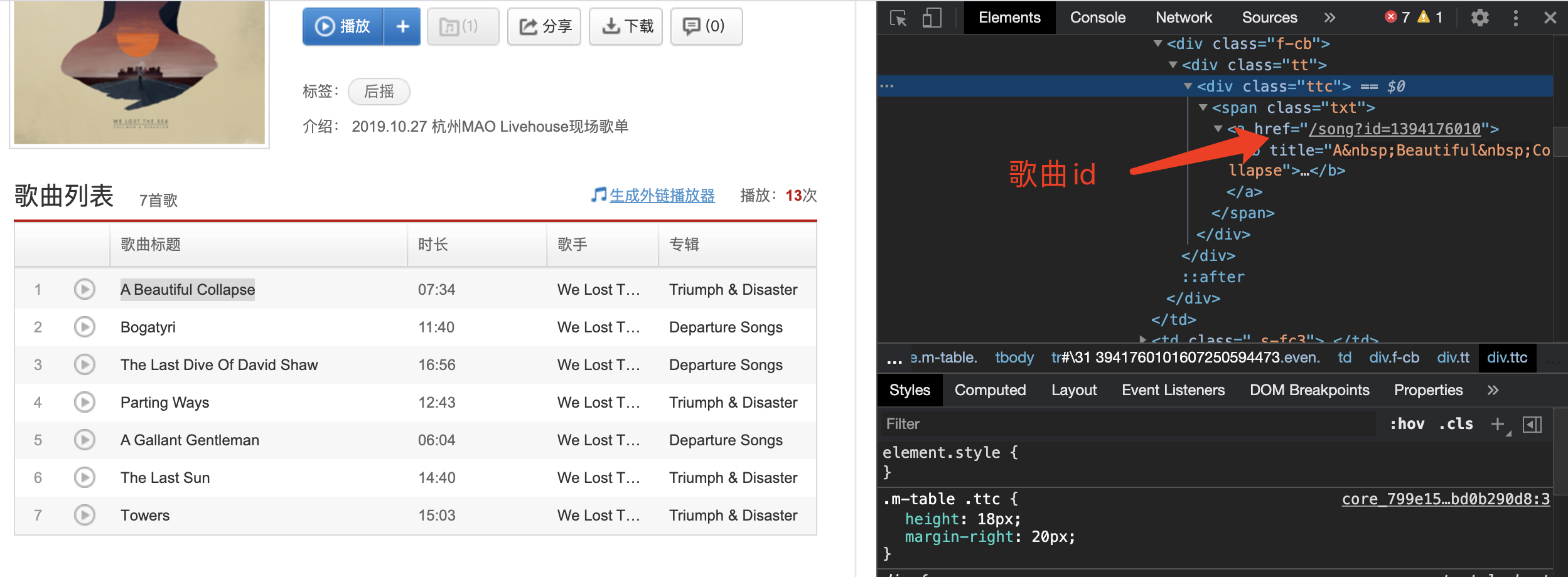
这样很容易我们就找到了这首歌曲的id,进而分析出该歌单的所有歌曲id都是存放在相同的标签和属性中。规则摸清了,接下来我们就利用Python帮我们去访问歌单页面,并且一次性获取所有的歌曲id。
抓取数据
这一步我们主要需要借助几个第三方库的能力,一个是request,通过urlopen()方法可以发起一个简单的web请求网页:
1
2
3
| req = request.Request(url=self.baseurl, headers=self.headers)
response = request.urlopen(req)
html = response.read().decode("utf-8")
|
现在我们已经可以访问到目标页面了,接下来需要借助非常强大有用的两个第三方库:BeautifulSoup和re,前者用来解析网页、获取标签,后者是一个正则库,可以指定规则匹配符合条件的内容。
1
2
3
4
5
6
7
8
9
10
| def analysis(self, html):
soup = BeautifulSoup(html, "html.parser")
bs4 = soup.find_all("li")
bs4 = str(bs4)
return bs4
def matching(self, bs4):
rule = re.compile(r'href="/song\?id=(\d*?)"', re.S)
id = re.findall(rule, bs4)
return id
|
批量下载
通过解析和匹配标签属性我们就拿到了所有id,只要遍历这些id请求下载外链即可,优化一点还可以在下载前获取歌曲的基本信息,这里需要用到requests和os库来请求并写入歌曲。不同于request,requests是对request的进一步封装,可以直接构造get、post请求并发起。
1
2
3
4
| saveurl = "http://music.163.com/song/media/outer/url?id=" + id
content = requests.get(url=saveurl, headers=self.headers).content
with open(self.path + songname + " - " + singername + ".mp3", "wb") as f:
f.write(content)
|
优化功能
虽然我们已经实现了批量下载音乐的需求,但显然它并不好用,想要下载必须要知道歌单地址或者歌手页地址,能根据搜索的任意歌手下载对应的歌曲才是符合实际场景的。没问题,整体思路也是一样的,只不过多加了一步解析歌手id的步骤。
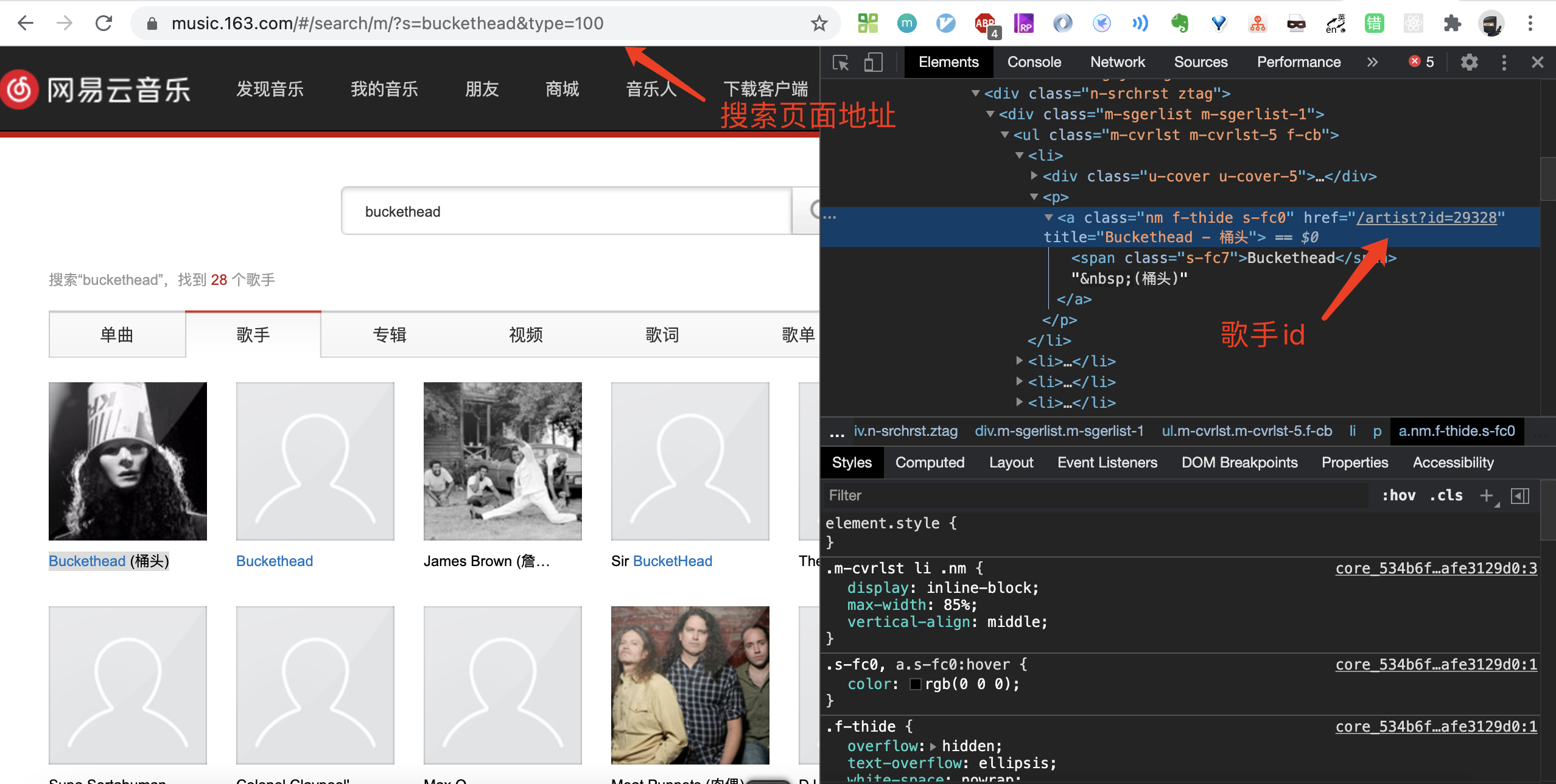
我们效仿解析歌曲id的方式去解析歌手id,可是这一回却发现我们没有匹配到对应的元素,经过一番查询,获悉很可能是因为这个歌手列表的内容是异步加载的,访问网页的时候并获取不到对应的结构。
看来我们只能换一条路尝试了,既然是异步加载那么数据肯定是通过接口获取的,那我们也可以通过模拟接口请求来获取查询的原始数据,很幸运这个接口也有人整理出来了。
所以整个功能的流程就是:输入歌手名称——请求查询接口获取歌手列表——显示排在前面的几个歌手选项——选取其中一个歌手——根据选取的歌手id访问歌手页面获取歌曲id——批量下载。
完整代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
| from urllib import request
from bs4 import BeautifulSoup
import re
import requests
import time
import getpass
import os
user_name = getpass.getuser()
class Music(object):
def __init__(self, baseurl, path):
head = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"
}
baseurl = baseurl.replace("#/", "")
self.baseurl = baseurl
self.headers = head
self.path = path
def main(self):
html = self.askurl()
bs4 = self.analysis(html)
id = self.matching(bs4)
self.save(id)
def askurl(self):
req = request.Request(url=self.baseurl, headers=self.headers)
response = request.urlopen(req)
html = response.read().decode("utf-8")
return html
def analysis(self, html):
soup = BeautifulSoup(html, "html.parser")
bs4 = soup.find_all("li")
bs4 = str(bs4)
return bs4
def matching(self, bs4):
rule = re.compile(r'href="/song\?id=(\d*?)"', re.S)
id = re.findall(rule, bs4)
return id
def save(self, id):
for i in id:
url = "http://music.163.com/song?id=" + i
req = request.Request(url=url, headers=self.headers)
response = request.urlopen(req)
html = response.read().decode("utf-8")
soup = BeautifulSoup(html, "html.parser")
bs4 = soup.find_all("title")
bs4 = str(bs4)
rule = re.compile(
r'<title>(.*?) - (.*?) - 单曲 - 网易云音乐</title>', re.S)
name = re.findall(rule, bs4)
name = name[0]
songname = name[0].replace(r"/", "_")
singername = name[1].replace(r"/", "_")
print("正在下载:" + songname + " - " + singername + "……")
saveurl = "http://music.163.com/song/media/outer/url?id=" + i
content = requests.get(url=saveurl, headers=self.headers).content
with open(self.path + songname + " - " + singername + ".mp3", "wb") as f:
f.write(content)
print(songname + " - " + singername + "-----------下载完毕。")
time.sleep(1)
return
def getArtistId():
content = input('请输入歌手名字: ')
searchUrl = "http://music.163.com/api/search/get/web?csrf_token=hlpretag=&hlposttag=&s=" + \
content + "&type=100&offset=0&total=true&limit=20"
result = requests.get(url=searchUrl).json()
artistList = result['result']['artists'][:3]
for i,artist in enumerate(artistList):
number = i + 1
name = artist['name']
if 'transNames' in artist:
name = name + '(' + artist['transNames'][0] + ')'
print("[" + str(number) + "]: " + name)
artistNo = int(input('请输入歌手序号: '))
return artistList[artistNo-1]['id']
if __name__ == "__main__":
artistid = getArtistId()
artisturl = "http://music.163.com/#/artist?id=" + str(artistid)
path = "/Users/" + user_name + "/Downloads/music/"
isExists=os.path.exists(path)
if not isExists:
os.makedirs(path)
artist_demo = Music(artisturl, path)
artist_demo.main()
print("\n全部歌曲下载完毕")
|
这样,一个简单的批量下载歌曲的Python小工具就完成了,你还可以继续丰富完善它的功能,快去试试吧!